Crash diet: finding spare bytes with request logs
2024-12-08
A recent Hacker News post caused a surge in traffic to my website, pushing me over my free-tier Firebase bandwidth limit1.
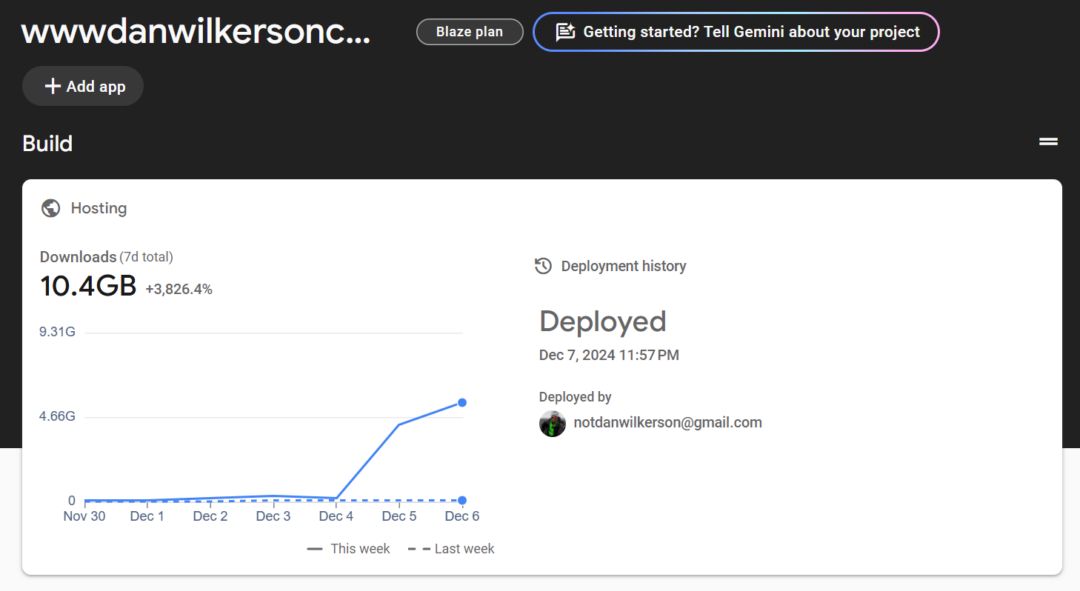
This surprised me because the submission wasn't that popular - a measly ~40 upvotes. I've had traffic surges from HN before with no issue. Time to do some optimization!
Finding the lede
There wasn't an obvious culprit - the post was 246 kB, I should have plenty of spare bandwidth. Maybe other parts of the site were getting hammered?
I went hunting for request logs in Firebase. Imagine my delight when I discovered the Firebase <-> Cloud Logging integration (full disclosure: I work on Cloud Logging, but this isn't an intentional advertorial - I didn't even know this integration existed!).
The culprits
Tools like du can spot large files, but that's only half the
picture. Combining the resource size with request count lets us see which files
are bandwidth hogs and will give us more bang for our optimization buck.
I'm using Cloud Logging stuff, but any tool that gets you request counts will do. The logs that Firebase forwarded included the request URL and response size of content on my site. Log Analytics2 is a neat feature that lets you run SQL against your logs.
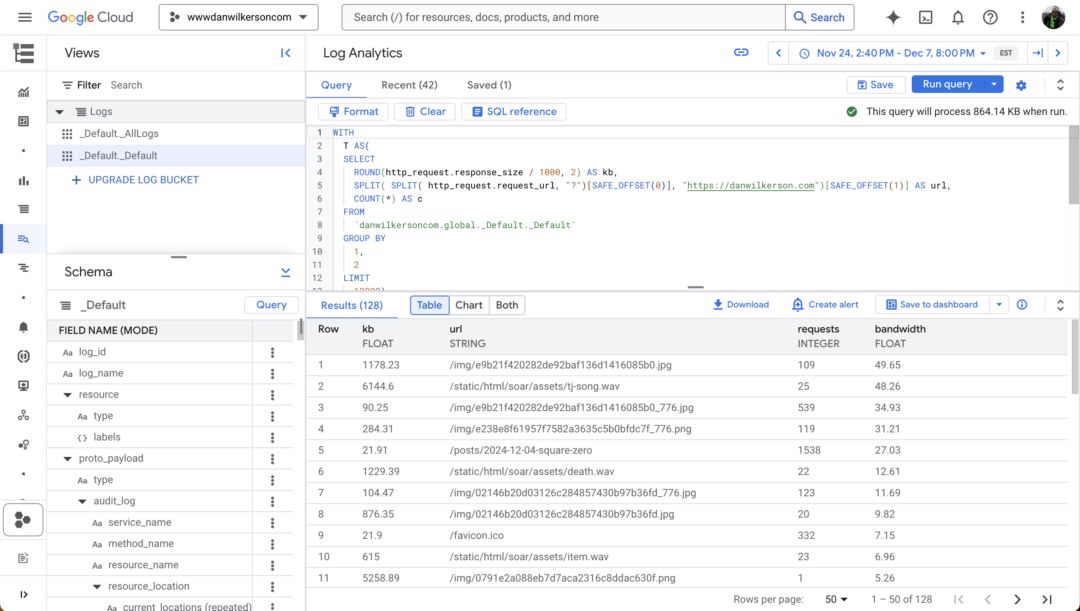
Now we've got a nice list of files, from most-bandwidth consuming to least.
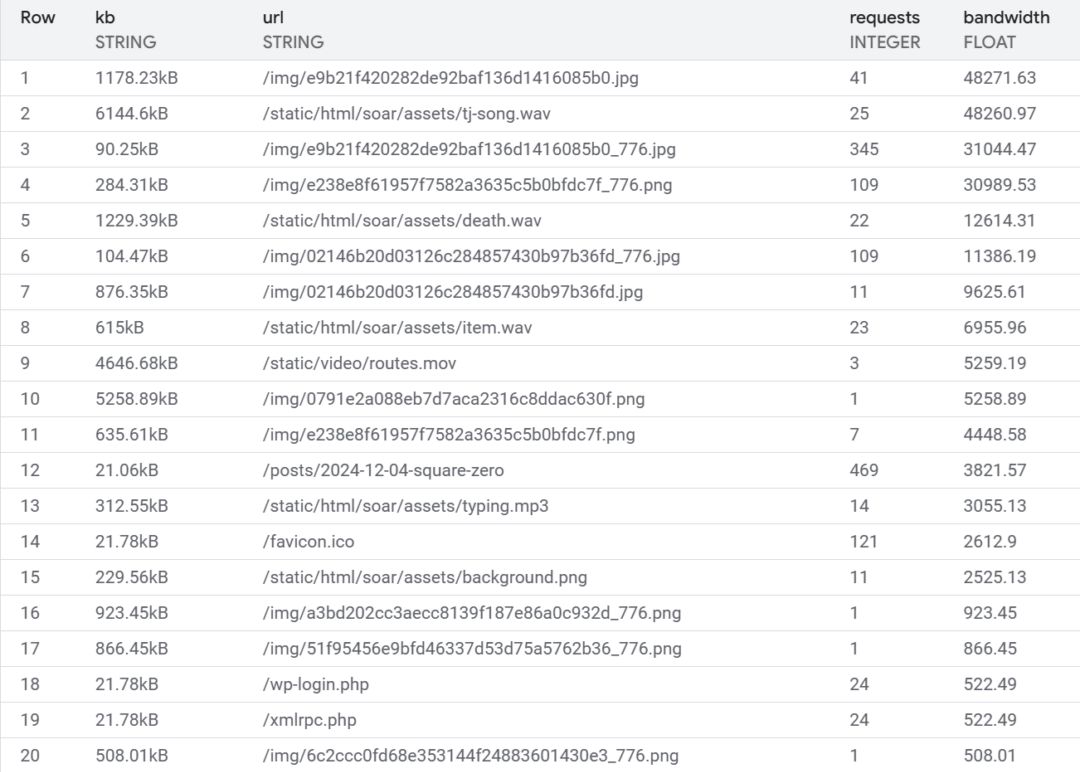
Let's look at a few patterns.
Original size images
Items like /img/e9b21f420282de92baf136d1416085b0.jpg are the full-size versions of
blog post images. I include links to full size images, such as photos of my keyboard wiring,
for detailed viewing. The optimized images included on the blog post have a link that points to the full-size counterpart.
<a href="/assets/img/full_size.jpg">
<img src="/assets/img/full_size.jpg" srcset="/assets/img/optimized_size.jpg
756w ...">
</a>
What's odd is that the links to the full-size versions are currently broken - who was requesting these?
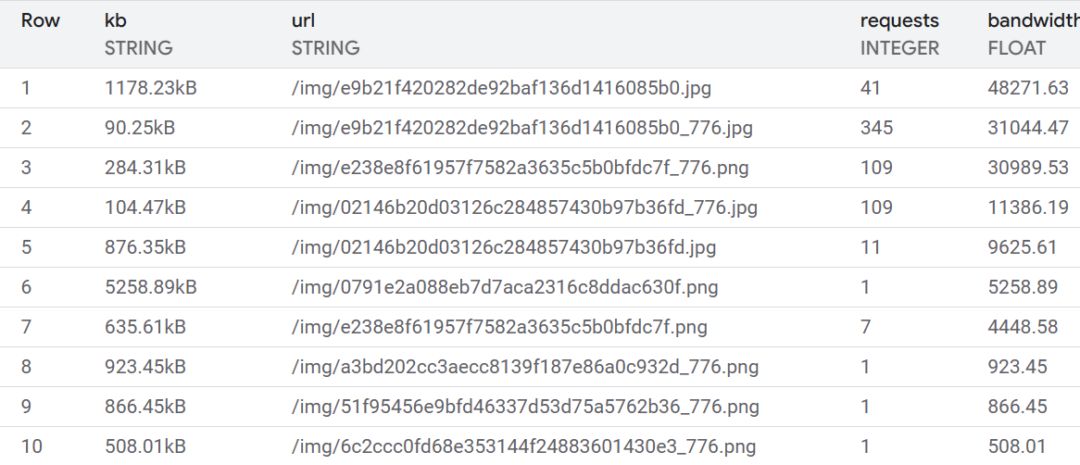
At first I chalked it up to crawlers, but then I did some digging and was
surprised to learn that srcset isn't fully supported everywhere. I checked the User
Agents for these requests; sure enough, lots of normal-looking traffic.
Without srcset, the src version is loaded - so full-size images for all
those users. Ouch! Sorry, folks.
To address this, I updated my srcset generator to resize/compress originals, too. I also had it
convert all png images to jpg. Our /img/e9b...5b0.jpg example above is now 152 kB - about 90%
smaller, much better.
Unoptimized assets
The Easter egg minigame contained large, unoptimized assets. The music
(tj-song.wav) is a dazzling 6.2 MB! These are all prefixed with /static/html/soar/....
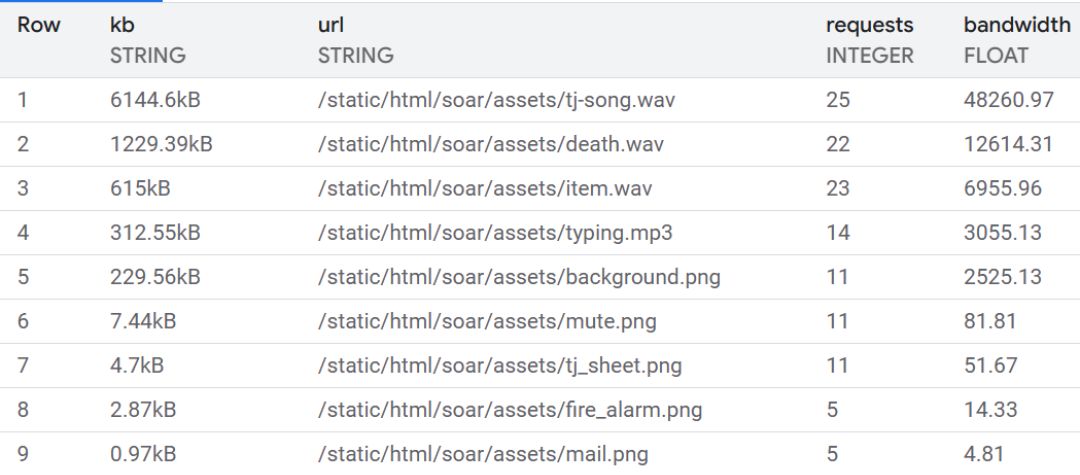
Note: Response sizes for streaming assets vary per request due to request chunking.
I converted the .wavs to .mp3s and optimized the background image. It's a
still-outrageous-but-more-reasonable 1 MB for the whole thing, now. Apologies to
John Carmack.
Non-existent files
The most interesting find was the bandwidth spent serving files that don't exist.
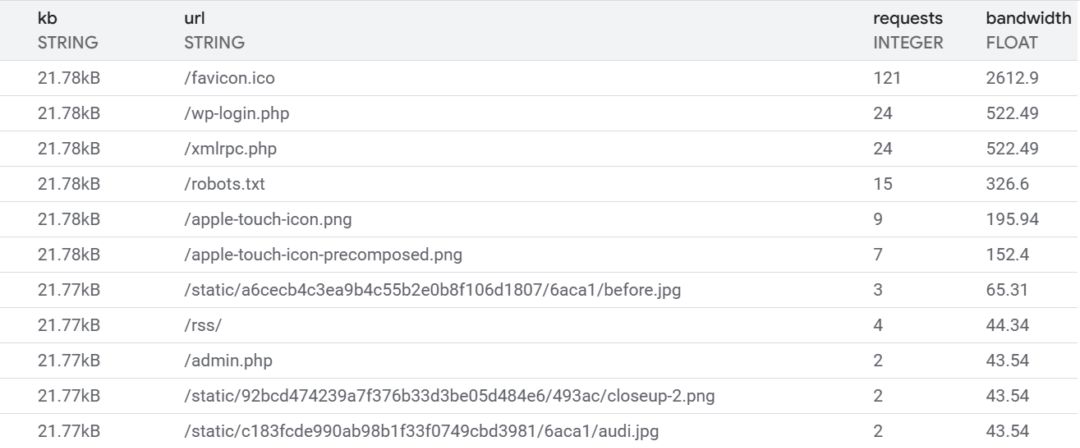
Lots of vulnerability scans of pages like wp_login.php. This itself isn't
surprising, but the bandwidth consumed was. The default Firebase 404 page is
21 kB - returning just "404" comes in at ~300 bytes. A very pleasing 98.6% reduction.
Adding empty favicon and apple-touch-icon files will save some bytes as
well. Finally, adding a robots.txt is a good site hygiene thing to do and will
save a few more kB.
Unresolved mysteries
There were some things I saw I haven't had time to dig into yet - for one, the response size recorded in the logs varied per request. I suspect this is just header noise, but it would be nice to understand it fully.
There were also some stray requests for files from the old Gatsby version of the site, again, probably from crawlers. It might be worth adding redirection rules in Firebase for those, though.