An unofficial Allegheny County real estate API
2015-11-02
NOTE: I get emails about this once in awhile; the whole dataset appears to be available here and this code is unmaintained and YMMV!
Allegheny County makes available a searchable database of public records on parcels in the area. It's a handy resource for homebuyers interested in knowing a little more about the history of a home they're purchasing, or to do some comparison shopping when preparing to buy a home.
I've always been interested in examining pricing data on Pittsburgh neighborhoods for fun, so about a year ago I put together a NodeJS package that exposes a few methods to scrape the site and return the data in JSON, e.g.:
acreApi.parcel.ownerHistory("0084-N-00285-0000-00", function(err, parcel) {
if (err) return console.log(err)
console.log(parcel)
})
Outputs:
{
"parcelId": "0084-N-00285-0000-00",
"municipality": "107 PITTSBURGH - 7TH WARD",
"address": "5801 WALNUT ST PITTSBURGH, PA 15232",
"ownerName": "BORETSKY ROBERT H & KAREN R (W)",
"deedBook": "10857",
"deedPage": "371",
"ownerHistory": [
{
"owner": "",
"saleDate": "",
"salePrice": 1
},
{
"owner": "ANN MEDIS",
"saleDate": "2/8/1993",
"salePrice": 33000
},
{
"owner": "BORETSKY ROBERT H & KAREN R (W)",
"saleDate": "9/1/2000",
"salePrice": 125000
}
]
}
I built it to provide a programmatic way of querying that dataset, which can be found here. The API makes it super simple to aggregate data on swaths of the Pittsburgh region for analysis. Here's a chart I built using the street.street and parcel.ownerHistory methods.
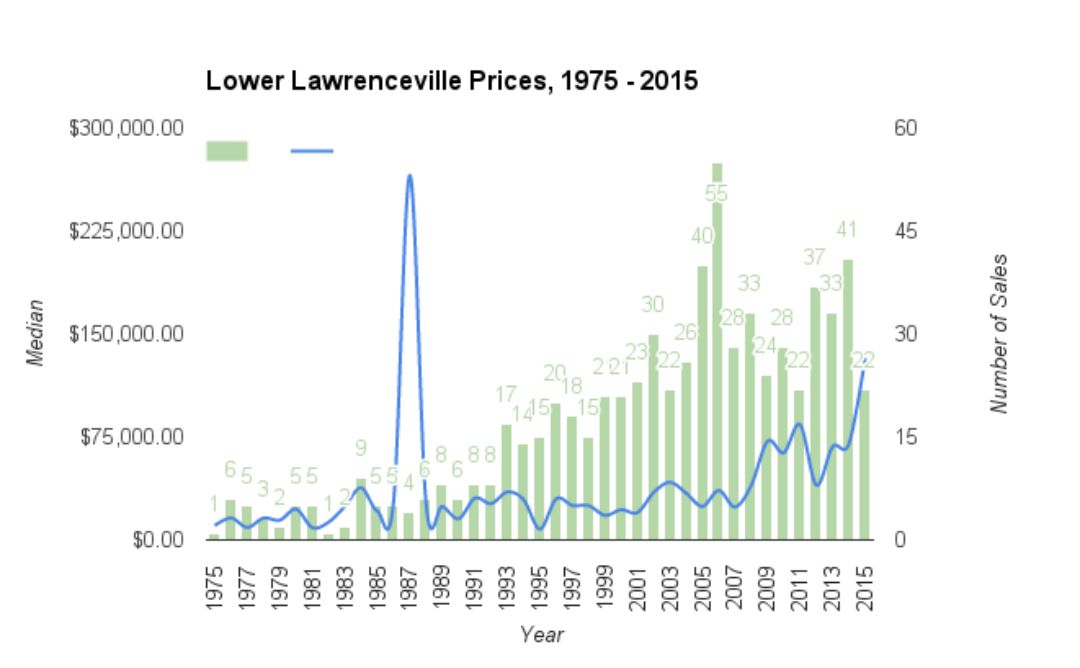
For folks who live in the area, the data suggests a fire-sale in the neighborhood between 2005-2007 (about when the new Childrens Hospital was announced and moved into the neighborhood), and steady price increases from then on as interest in the Lawrenceville area has stretched into the further reaches of the neighborhood.
This was an interesting project for me; there were many challenges to overcome. I learned a little about .NET applications and how they work, and a lot about managing multiple simultaneous requests in Node. Some more interesting problems I solved include:
- Scraping data from the application, which uses stateless URLs
- Queueing/managing requests responsibly
The Allegheny County Real Estate search tool doesn't store state information in the URL, meaning I couldn't just create a method that plopped in query parameter values and returned the data. Instead, it uses data POST'd on each query or refinement that the app returns data about on the same URL.
To get around this, I had to spoof the View Statedata the .NET application expected in order to get back any meaningful results. As it stands, I'm spoofing View State information by GET'ing the /search.aspx page, extracting the information from the HTML (View State and other .NET data values are stored in hidden inputs on the page), and then proceed. This View State information would then be cached and re-used or re-written as the scraper interacted with the site.
This introduced a challenge for kicking off multiple concurrent requests when no View State has been cached. For example, if I had some code like this:
async.map([
'Howley', 'Cabinet', 'Mintwood',
'38th', '39th', 'Liberty', 'Penn'
].map(function(el) {
return [el, 'Pittsburgh - 6th Ward'];
}, function(arr, callback) {
acre.street.street(arr[0], arr[1], callback);
}, function(err, results) {
...
});
If no View State was cached, each street being hit by async.map would cause a GET request to be issued in order to establish an initial View State - that would mean 7 immediate requests, when 1 would do.
I solved that by adding an internal queuing mechanism to the State manager, found in /lib/State.js.
var _gettingState = false;
var _storedState;
...
_State.get = function StateGet(callback) {
if (_storedState) {
callback(null, _storedState);
} else if (_gettingState) {
_queue.push(function() {
callback(null, _storedState);
});
} else {
_gettingState = true;
Api('get', 'search', {}, function(err, html) {
if (err) {
_gettingState = false;
callback(err);
} else {
_storedState = Parser.stateData(html);
if (_gettingState) {
_clearQueue();
_gettingState = false;
}
callback(null, _storedState);
}
});
}
};
function _clearQueue() {
_queue.forEach(function(el) {
el();
});
_queue.length = 0;
}
When a part of the API asks for a View State, the State manager returns the cached View State or it builds a new one. If additional requests come in during the process of fetching and building the View State, the State Manager caches the callback in a private queue and defers them until the View State is constructed. Once the View State is in place, _clearQueue iterates through all cached callbacks and passes them the newly created View State. No unnecessary requests required!
When I need to get at pages further in the application, say, paginated results, I manually scrape links to those pages and request them individually. This is a bit of a slow and sloppy mechanism, and it's very fragile; any semi-serious changes to their naming conventions would break the whole thing. If I could do it again, I would be interested to try and manually build View States and POST those directly, instead of the more spider-like approach I'm taking now.
The other challenge I ran into was responsibly managing all of those requests; left to it's own devices, the API could generate hundreds of requests to their server instantaneously. Rather than litter in setTimeout's all over the place, I built a Connection manager to handle queuing, executing, and pacing the requests. That can be found in /lib/Connections.js. Since then, I've spent more time building similar mechanisms, so this experience was valuable. Here's the code I'm using to doit:
// Manage our requests to prevent overloading the server
var Connections = (function Connections() {
var _Connections = {}
var _queue = []
var currentConnections = 0
var maxConnections = 20
var check = function ConnectionsCheck() {
if (currentConnections < maxConnections) {
var availableConnections =
maxConnections - currentConnections < _queue.length
? maxConnections - currentConnections
: _queue.length
process(availableConnections)
}
}
var process = function ConnectionsProcess(num) {
var i
for (i = 0; i < num; i++) {
_queue[0]()
_queue.splice(0, 1)
currentConnections++
}
}
_Connections.add = function ConnectionsAdd(item) {
_queue.push(item)
check()
}
_Connections.remove = function ConnectionsRemove() {
currentConnections--
check()
}
return _Connections
})()
module.exports = Connections